One of the things that frustrates me with having a local music library is the tedium of tagging. While there are tools (like beets or MusicBrainz Picard) to make it easier, I feel there are fundamental issues with the design of tags for music, and the way we apply tags. This doesn’t just make exploring music harder, it leaves a lot of possibilities on the table that will be very hard to implement without significant changes to our approach.
Schema design: Who needs normal form?
Good database schema design teaches us to avoid duplication. Having duplicate data isn’t just wasteful, it’s actually (perhaps counter-intuitively) fragile. This is one of the big tenets of relational database design – the notion of normal form. Why store album information in the song table, when you can store it in an album table, and do a join instead?
Unfortunately, tagging formats never really got this lesson. This is likely because of two factors – there’s no standardized way (but plenty of proprietary ones) to have metadata in an attendant database, and many people only download the songs they cared about. This meant that the metadata about not just the song, but the album holding it, went into the the song’s file – a violation of normal form. It gets not just conceptually problematic, but actually wasteful when you have album art and potentially other parts of album packaging in the file’s metadata – megabytes of images, per file. Of course, people usually make the images separate files, but it’s still not applied consistently beyond heuristics for what the front cover is called.
Incorrect or incongruous metadata is just a mild annoyance if you only have loose MP3s you collected from Napster and dropping into Winamp. If you’re trying to manage a music library, it becomes incredibly annoying. Individual tracks have no relation to each other, and you can only use heuristics within the tag, or maybe their place in the filesystem hierarchy, to determine if they’re logically grouped together. If the user’s data is subtly wrong between some tracks, but not the others, they’ll appear split up within the library. This requires re-tagging the tracks, on the file level, or perhaps more likely, in your software’s database representation of the library, which is more efficient than consulting the separate files. It’s a lot of effort to spend, and mistakes make a catalog less useful.
While not fatal, also annoying is the rigid tag scheme. This usually means further information (such as a remaster, performers, featured artists, remix including variant and remixing artist, etc.) is usually fit into album or song titles. Who wants to see a mouthful like “Track (feat. Rapper) [2019 Remaster] (Live at Concert Hall) (EDM Remix)” – especially without any consistency? Or have to worry about if the year on an album should be the date of original issue, or the date of its reissue? Or how to handle the most prolific musician of them all, Various Artists? What about different transliterations or translations – is “Molchat Doma” the same as “Молчат Дома”? Tag formats occasionally offer extended metadata as a better place to put these, but they’re rarely used, or rarely used in a consistent matter, if even present.
There’s also user data like play counts and ratings too. These can be put into the tag, but would pointlessly modify the original file, with the integrity and sharing issues that has. Not to mention the common case of holding files on a read-only medium like a file share.
All of these issues aren’t theoretical either. I dealt with inconsistent metadata before (one such example), and it only became a problem because some software applied different heuristics over some kinds of metadata. Efficiently correcting it was a pain. It’s not good that we’re trying to construct a relational database out of several disparate little files, with inconsistent amounts of rigour put into them. It feels like an inversion of how a database should be built; when we have to manipulate the file instead of running simple queries, it’s a flashback to the bad old days.
Sidebar: Julien Voisin has a blog post where he covers many ugly edge cases that tag schemas don’t handle well. The post is more about bizarre names that fit into existing schemas, but it’s worth reading to see how poor some software’s assumptions can be.
Schema design: more structure, more assumptions
Audio tagging is designed around the assumption that it’s music that has tracks in albums, made by usually singular (as in a single person or group) artists. There are some variations around this model, but systems are generally based around this core assumption. While some formats are more freeform name-value internally, the way most software surfaces this to a user is the fixed artist-album-track hierarchy. Arguably, tagging is a bit of a misleading term, considering people associate that more with freeform tags that are less intrinsic to the work itself. (Hillel Wayne covers tag systems in that context in this article, if you want a refresher.)
Our current tag systems were designed for music, but people have audio in other forms too – audiobooks and podcasts being notable examples. The two have been wedged into this hierarchy, but it can be tricky to adapt in a consistent or logical manner. Is the “artist” the narrator of the book, or the author? Is a season of a podcast the “album”, or the podcast itself? These might not be music, but people use normal music players to listen to them, so their tags are also worth considering. There’s also other kinds of audio too, that doesn’t even map well at all to current tagging – field recordings, loose audio snippets, etc. – I can’t begin to think of how to tag these properly.
The way we tag music is also a poor fit beyond “modern” popular music of the Western tradition. For example, Western Classical music has less emphasis on the “performer” (what we consider the artist tag; some formats internally call it performer though), and more on the composer (which is off to the side and rarely filled in by most people when tagging). Anastasia Tsiouclas of NPR and Charles Petzold have articles covering this in more detail. That said, Apple also bought the classical music streaming service Primephonic a while back, so perhaps the state of classical music tagging might improve for Apple Music users. I’m not familiar enough with other kinds of musical traditions, but I have to imagine this could be a problem for them too.
Versions and cataloguing: WEMI and friends
The library cataloguing world has been dealing with the issues of metadata for decades. While mostly focused on the issues of books (in physical and nowadays, digital form), they’ve had to deal with many other kinds of media, many of the issues they face have equivalents for dealing with a personal music catalog. For a very in-depth overview of the metadata and schema issues dealt with there (and the conflicts between them), I strongly recommend you read Karen Coyle’s FRBR: Before and After. I’ll just be scratching the surface.
One of the most interesting notions is some kind of separation – the FRBR model (and its many confusing descendants) uses the work, expression, manifestation, item scheme, or WEMI for short. The idea is to represent something in its most abstract (the artistic idea, the work), then relate it to more and more concrete forms (such as the English-language version of a text as the expression, the paperback book published in 1996 as the manifestation, all the way to your copy of it as the item). This makes it easier to group related things together – different publishers’ version of the same book, different language versions, etc. Without some kind of form of expressing this, it would be very easy to get bogged down by several duplicate or irrelevant results when looking up a book.
Of course, it’s not all that simple – there are other views on how to relate different levels of abstraction (especially in how it affects user experience for finding something), what changes require a new WEMI-level item (what’s the criteria for i.e. a new manifestation? is a compilation a work?), the relations that result with translation and annotation (making it not quite a simple linear relation), and what properties belong to what level of abstraction (is the key a song composed in a property of the work and/or the expression?). In particular, there are many competing views on the relations between the abstract and concrete should be laid out. Explaining the differences between them would take a lot of time, so I defer to Part 1 of FRBR: Before and After, where you can check out various library scientists’ perceptions if you wish to learn more.
Sidebar: For an example of how all of this is applied for music in actual libraries, take a look at Best Practices for Music Cataloging. There’s a thick layer of it being practice (in RDA/MARC) for librarians (who are also dealing with the physical items too, whereas you may not be) rather than theory for the layman, but it doesn’t assume too much prior library science knowledge. While your personal tags might not need such rigour, it demonstrates how WEMI is applied for things like popular music on a large scale. And if you’re pulling metadata from an authority that has a lot more stuff and knows more about it, you better hope it’s rigourous.
Some examples
While the various kinds of separations are up to debate in the cataloguing community (as is schema design in general), having some form of them is useful. I myself am not too picky. There may be albums, but there’s various versions issued for different countries in their physical form, even if the contents are identical. The variations in physical form might not be too relevant for modern digital music, but it would affect packaging like album art and booklets – the former of which is usually included in your file’s metadata, the latter occasionally as an attendant file beside it. Sometimes the contents aren’t identical – albums have changed their contents for various regions. For example, Depeche Mode’s Speak & Spell has a different track list for the US and UK version of the album. Not to mention if an album is reissued with additional tracks or a remaster of the original tracks – pretty much any sufficiently old album will acquire these kinds of variations, and there’s a chance you might want multiple versions of the album. Why shouldn’t that be cleanly representable?
There’s also more complex cases too, and they’re surprisingly common. Kanye West’s The Life of Pablo had the track list changed soon after release. David Byrne and Brian Eno’s My Life in the Bush of Ghosts had a controversial track omitted on its re-release. Metric’s Grow Up and Blow Away was distributed amongst the underground scene for years, but had its track list changed for its official release. Kraftwerk’s albums were changed for the US versus German markets. Numerous albums keep getting reissued in box sets (sometimes with other albums combined – significantly complicating relationships in a schema), extended track lengths, or simply with different artwork. What if you want either version?
The scheme could also be extended to other things as well. As a very simplified WEMI-ish model, imagine the “essence” (for lack of a better term) of the song (which could be decomposed further – arrangement, lyrics, etc.), and “renditions” by various artists, including covers, remixes, censorship, and mastering variations. Or relating an individual artist or composer to the bands they were in. Unfortunately, this would require metadata reaching outside of the traditional per-file approach.
Missed opportunities
What could we do if the state of things were better? Right now, we look at music libraries as a collection of songs, and only an ill-defined, ad-hoc hierarchy of tags binding them. If we flipped the script and made metadata the focus, I think we could have nicer things.
Even within songs, we could have richer information. Imagine being able to find all the covers of a song, or alternative versions. Or the opposite – have all the duplicate versions of a song’s rendition across albums, reference all the other albums, and de-duplicate the versions on disk. Artist information, album packaging like booklets, and other such data that’s de-prioritized in the systems we have now could become first-class concepts that you can browse, instead of being figured out from metadata. These might not exist in the form of files, but they’re important information.
The possibilities here suggest integration with a larger system providing authoritative data. For example, a lot the information you would want could be derived from sources like Allmusic or Discogs. The semantic web (brought up a lot by library science people) also has a lot of promises for even personal music libraries, which could take the silo nature out of your sources and provide a scheme for sharing facts about things. It’s unfortunate about its stillborn growth as the the real Web3. Or even something smaller scale – imagine playlist portability between services, if they point to the same identities for each track.
Ultimately, I find it sad that the local FLAC collection enthusiasts are stuck in their ways when it comes to not wanting music libraries. It also makes me wonder if we’ve been focusing too much on raw files in general, beyond music. Are they the wrong level of abstraction for human-meaningful data? Could we have better user experiences by some layering on top? Or using some kind of database instead of files? It’s an interesting thought I’ve been grappling with, but that’s a topic for another day…
Appendix: The state of streaming services: a very small case study
It’s interesting to note some streaming services can make somewhat of a break from things; I’ve subscribed to Apple Music to give it a try (I have too much obscure music locally to not have a collection, but streaming is useful for discovery.). They can offer a lot more related media (like time-synced lyrics, music videos, and curation via playlists and reviews) than the frozen state of affairs with local music libraries. However, due to compatibility, they still have to work within existing tagging concepts, and this can lead to confusing incongruencies between tags the user sees.
For example, the New Order album Movement is unfortunately labelled with additional text on the album and track names to indicate that this is a remaster with additional bonus tracks (a case of an unfortunate lack of proper tags to indicate versions), in additional to an editorial:

But you can also see, there’s a crude WEMI-like separation, because we can pick the original version of the album (as well as see things like music videos related to the album):

But it’s not all roses. Of which of these versions of Pere Ubu’s The Modern Dance, which one is the authoritative version? Is there really such a thing as an authoritative version? As far as I can tell, these only differ by track length; it would be useful to have more metadata like the issue number from the label to determine which is which. And how did it even decide on this version being the default anyways?

Other albums can be even denser with options, though what version you have may not be obvious as well. Halsey‘s If I Can’t Have Love, I Want Power has five different versions available, though one can tell from the title what expanded version they are, and from the explicit indicator on the album for a non-censored version (and for this album, down to the album art). Other times the alternative mix isn’t obvious. For example, the Atmos mix of Talking Heads‘ Fear of Music sounds different enough what version one prefers is probably subjective. One can only tell what they’re looking at by looking at the mastering notices at the top (i.e. digital master, lossless, Atmos, etc.).
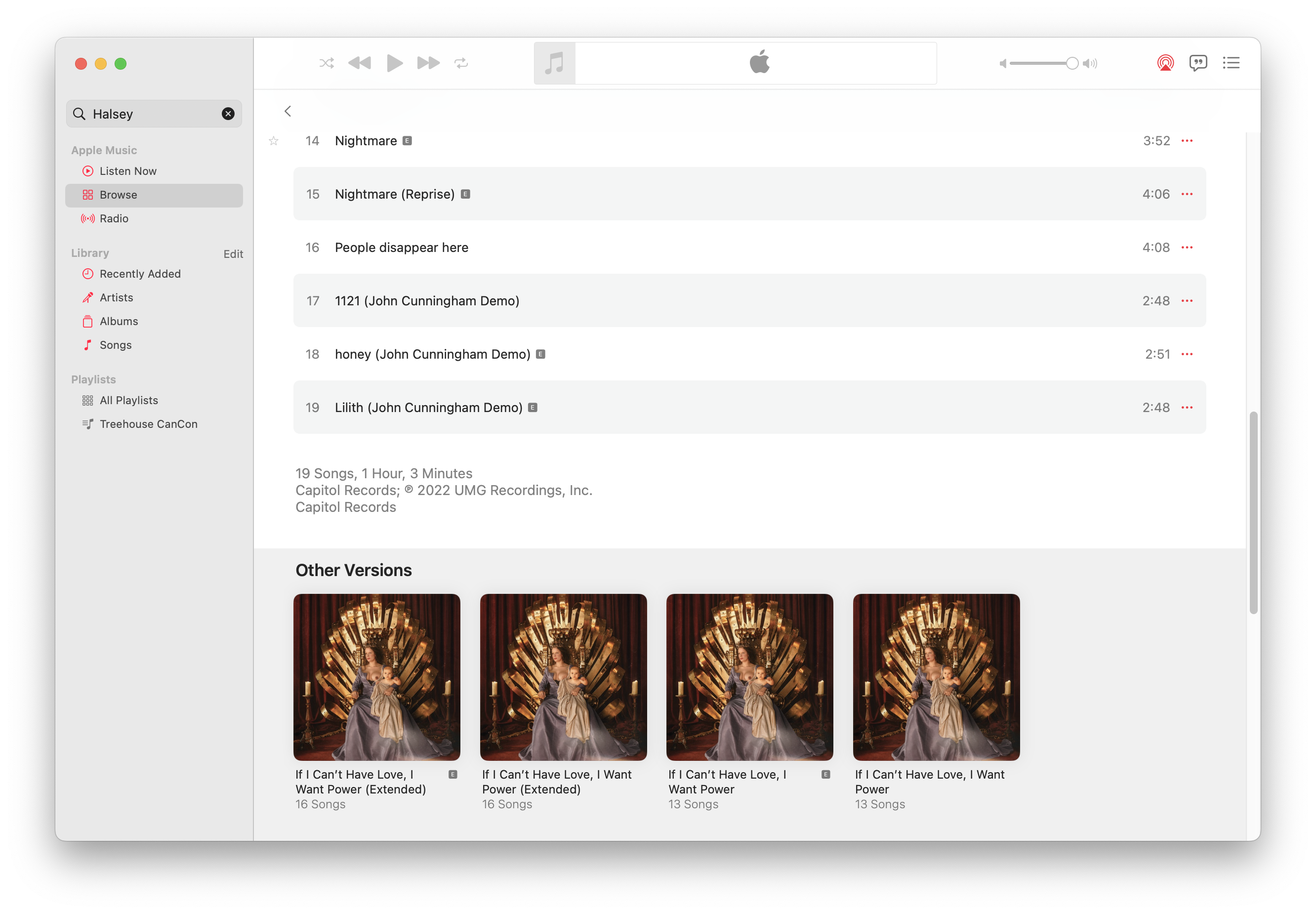
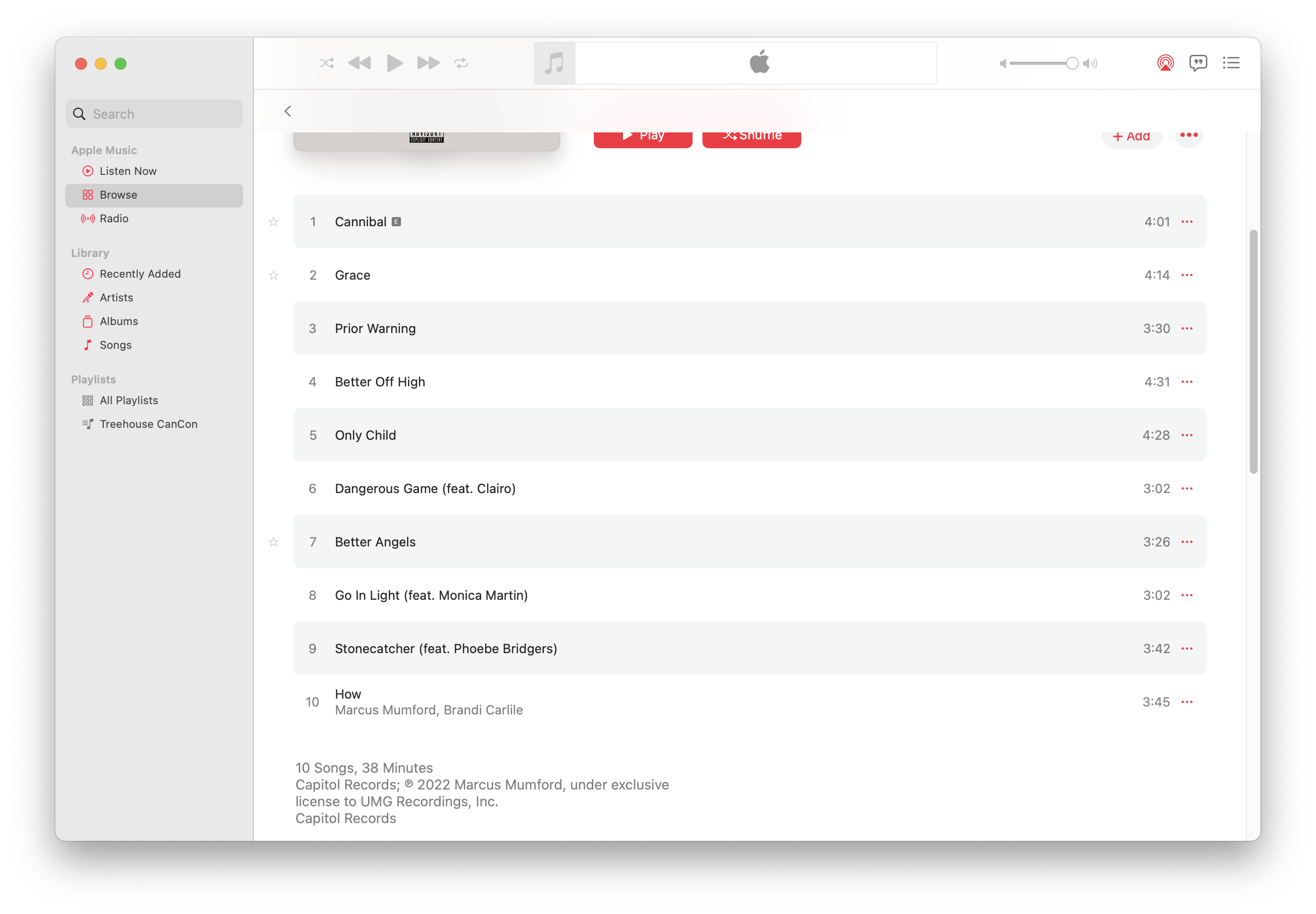
For just annoying-if-you-think-of-it-too-hard, here’s Marcus Mumford‘s new not self-titled album, (self-titled), with inconsistent titling. Or Caetano Veloso and David Byrne’s live album with inconsistent live markings?
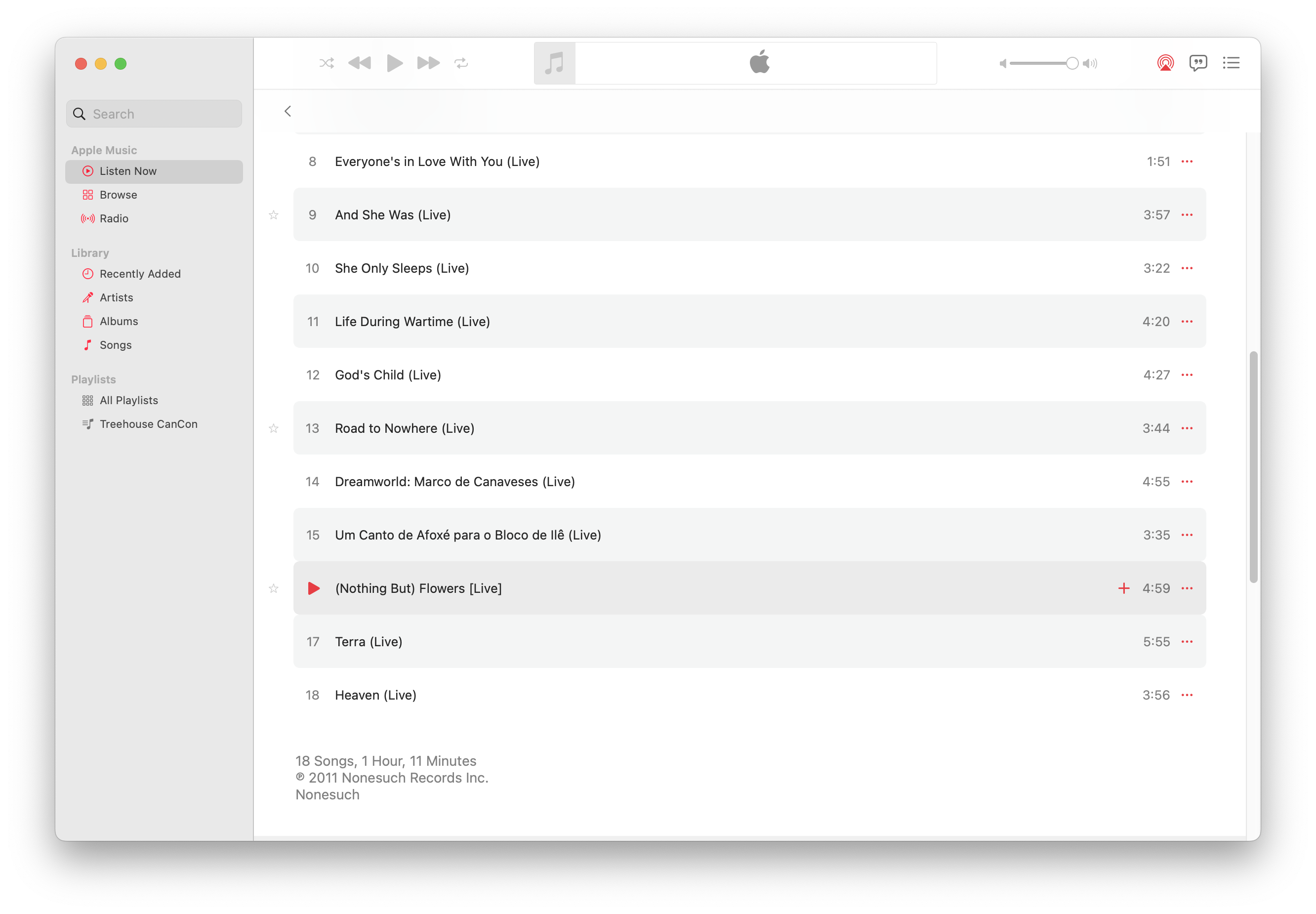
For a slightly more complex case of how metadata can be confusing, let’s look at Current 93’s The Inmost Light, a “box set” of two EPs and an LP from 1995-1996 that was issued in 2007. The actual albums inside are presented as discs on a single album. Despite the issue state being 2007 (and Apple Music displaying it as such), if you look at the songs’ metadata, it displays the original issue dates of each of the constituent albums (which are made unclear), and an inaccurate “n1 of n2” count.



Fixing all this looks like a hard job – it’s hard to add proper metadata at such a scale.
You are just beginning to touch the topic. I’ve recently been writing software to manage my library of about 1000 CDs, plus re-ripping and retagging them all. What a mess.
We have had albums since the first commercial 78s. For those too young to remember, a 78 only held about 3 minutes of music. One song. So an album was a collection of physical disks, with one song on each side. The Beatles and other groups in the 1960s revolutionized the album, it was designed to be listened to in a specific order. Much like movements in a classical piece.
Not only is tagging terrible for all the reasons you say, but the tagging software focuses on ease of use over accuracy. One click and you are done. As long as you don’t care about everything you complain about and dozens more issues. Sigh.
As least I’m shaking some rust off the gears in my brain that relate to programming. And listening to some great albums. Joni Mitchel’s Blue and Stoned Soul Picnic: The Best Of Laura Nyro are amazing.
A decade or so ago, I was the long-time lead developer for a popular freeware Music Player (in fact, you mention it in the 4th paragraph), and I’ve gone on this same spiel to many friends and colleagues. One of them found this article and sent it to me.
I can think of many more problems, such as – do I want to group “Tom Petty” and “Tom Petty & the Heartbreakers” together in the Media Library? What if I want to search for every group that Robert Smith has been part of? How do I separate the “canonical” albums from a band from the singles and EPs and bests of? Spotify tries to do this with mixed success, but they have the same issues with the year that you mention.
I also had a long conversation during the boredom of the early parts of the pandemic about classical music tagging with a retired classic music radio station employee. There’s a whole range of problems there. You are correct that the metadata schema is built around western rock and pop music.
There’s also the issue of metadata that is intrinsic to the song (the name of the song, who the songwriters are, the performers, etc) that is separate from metadata that is personal to you, such as the genre, any “tags” or the rating.
It’d be a fun one to fix, but outside of a few of us purists, I’m not sure who would even take advantage (much less help build the required database!). It would also take substantial modifications to the existing tagging schemes like ID3v2 (FLAC and others are more freeform) or just heavy use of private/custom fields.
You mention “normal form” and of course one major source of problem is that all of this metadata exists at the track level – on a single file, and must be trivially separable if it’s copied.
When I once looked at solving this problem (a decade ago), I came up with a few fingerprinting schemes to re-link a user’s database to a file that’s been moved (such as copied to dropbox or uploaded to an iPod). Mostly taking a hash of the audio portion of the file with the metadata and headers removed (these are subject to change). This helps for one’s personal collection, but otherwise identical files between two users might differ (CD ripping errors, CD drive read offset). Audio fingerprinting works here, but it might not be able to tell apart the same track on re-issues of albums or between the album version and the best-of version.
Anyway, enough ranting. If you are ever interested in building the solution to this, please reach out!
I’ve been banging my head against that wall for more than ten years, and boy, there’s so much to add to the “scratch the surface” and “just beginning to touch the topic” themes.
Let’s air grievances!
In a way my requirements are quite limited: no streaming, no dealing with individual songs, just albums, and only flac when it’s possible.
So about ten years ago is when I realized I would have to live in a small apartment (moving to Paris) and I would have to rip my already large CD collection: 3000 CDs at the time I’d say. Since then I’ve added quite a few downloads, bought more CDs, and ripped a bunch of stuff I borrowed in lending libraries “médiath`eques”.
One thing that’s improved: the online databases like gnudb.gnudb.org are much better, and you don’t have to deal with so many entries in Japanese. One thing that’s much much worse: one by one, music players are converting from a playlist-based format to one that trawls through your music directories and builds a one-size-fits-all database. There are not many old-style players left: in the FOSS world Audacious and Deadbeef are still there at least. Some time ago Clementine converted to that new dreadful approach. Thas was years after Audirvana converted to the database approach, when several of us complained about this on the offiial discussion list, with detailed explanations of the problems it introduced, all to no avail.
The mismatch of expectations between Pop and Classical (to use a very simplified terminology) has already been mentioned. But what if you, like me, also listen to jazz and free improvisation and “experimental” electronic music ? A good efficient metadata tagging system would be different for every style. I tend to edit the flac metadata, but not according to a formal scheme, but one that makes it easy to read when you look at the playlist. Things will move from field to field given circumstances like text length.
If you have a really large and varied music collection a database approach to music players is currently useless. I downloaded a recent trial version of Audirvana, and the search facilities had much improved since the last time I’d looked. But searches are still really tedious. Regexes would help, but don’t count on them to appear in a consumer product. There was a time when on some database-centric music players I couldn’t scroll to the cut I wanted because the mouse resolution wasn’t good enough. It’s still that way with the UPnP server on my CD/DVD/SACD player.
My current default music player is cmus, because the playlists are all-text so they are easy to edit and script. Cmus is not maintained anymore and doesn’t play that well with current Linux audio but on MacOS it’s able to adapt the soundcard’s sample rate to the file being played automatically.
I had a high-school friend whose father was a scholar. His home office/library looked like a mess, and it seems there was no organizational scheme to it, at least for ordinary humans. But but when you asked the old man for something he’d find it instantly. My NAS music store is 3.6 GB right now, almost all flac, and it’s kind of that way. Although I have to resort to little scripts to help me find stuff.
This is a plea to developers who happen to read this: I you want to launch a new music player, WHY DON’T YOU TRUST MUSIC LOVERS instead of the current metadata tagging nonsystem? As for myself, I intend to use a tagging filesystem like tmsu on my NAS, so I’ll be able to produce playlists from specs. That should play better with the new crop of music players, if you can present them with reduced virtual directories instead of the whole gigantic mess.
I want to thank the OP for making me learn about WEMI and I’m sure it will be very useful if there ever is a concerted effort to formalize a music classification system. But that will be successful only if a W3M-like consortium is assembled.
> This is a plea to developers who happen to read this: I you want to launch a new music player, WHY DON’T YOU TRUST MUSIC LOVERS
Because the number of users was shockingly small (in the hey-day of mp3 music playback software – late 90s to early 2010s). On Winamp, less than 10% of users even used the media library.
These days, I’d love to build some sort of “music lover” software as a hobby project, but as you’ve mentioned, it would take buy-in from a critical mass of software in order to make it functional.
What? Are you saying that 90% of people who use something like Winamp don’t keep a collection of music files on their hard disk?
I can understand that musical habits differ from user to user. But then why is it that so many music players (and more of them all the time) ask you for the keys to you music collection first thing after you fire them up for the first time? There seems to be a mismatch between developers’ perception and actual usage.
I don’t have anything in principle against a big database in a music player. I just want it not to be built blindly, relying solely on flac/mp3 etc metadata, since we all agree it’s shitty. Some feedback from the users is needed, and especially some consideration of the structure of their music file directories, which they may have been curating for years. That’s what I mean by trusting the music lover.
I don’t think it requires a lot of manpower to get this. It could be achieved by tweaking a current app, or by building some kind of middleware to feed a backend like mpd. A non-destructive overlay over the current tagging system would be a nice way to di it. We know that a lot of successful FOSS apps present a nice non-threatening façade to the beginner but have incredible tweaking resources beneath the surface for the maniacs among us.
> 90% of people who use something like Winamp don’t keep a collection of music files on their hard disk?
I’m saying that the vast majority of users are just managing their files in the file system, and not using an application (With sorting / indexing / cataloging), even when it’s available in the music player application they are using to listen to those songs.